Cumulative Attribute Space for Age and Crowd Density Estimation CVPR'13
Introduction
A number of computer vision problems such as human age estimation, crowd density estimation and body/face pose (view angle) estimation can be formulated as a regression problem by learning a mapping function between a high dimensional vector-formed feature input and a scalarvalued output. Such a learning problem is made difficult due to sparse and imbalanced training data and large feature variations caused by both uncertain viewing conditions and intrinsic ambiguities between observable visual features and the scalar values to be estimated. Encouraged by the recent success in using attributes for solving classification problems with sparse training data, this paper introduces a novel cumulative attribute concept for learning a regression model when only sparse and imbalanced data are available. More precisely, low-level visual features extracted from sparse and imbalanced image samples are mapped onto a cumulative attribute space where each dimension has clearly defined semantic interpretation (a label) that captures how the scalar output value (e.g. age, people count) changes continuously and cumulatively. Extensive experiments show that our cumulative attribute framework gains notable advantage on accuracy for both age estimation and crowd counting when compared against conventional regression models, especially when the labelled training data is sparse with imbalanced sampling.
Contribution Highlights
- For the first time, an attribute representation is constructed for learning a regression model.
- A novel concept of cumulative attributes is proposed with both clear semantic meaning and also discriminative, with added advantages of efficiently computable and requiring no additional annotation.
- Extensive experiments on both age estimation and crowd counting benchmark datasets demonstrate the superiority of our method over the state-of-the-arts, especially when the data is sparse and imbalanced.
Citation
Images

Age estimation and crowd counting both suffer from sparse and imbalanced training data distribution. Top: FG-NET facial age dataset. Bottom: UCSD crowd dataset.

The pipeline of our framework compared with conventional regression framework.
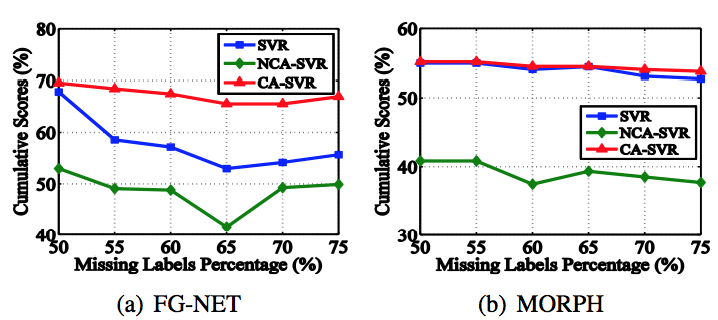
Age estimation performance with sparse and imbalanced data measured using cumulative scores (the higher the better).

Crowd counting performance measured by mean deviation error (the lower the better).


Visualisation of the importance of different features for cumulative attributes. Weights of each type of features were averaged for computing the weight ratio between different types of features.
Datasets and Codes

A dataset collected from a publicly accessible webcam for crowd counting and profiling research. Over 60,000 pedestrians were labelled in 2000 video frames.
Details ...