Feature Mining for Localised Crowd Counting BMVC'12
Introduction
This paper presents a multi-output regression model for crowd counting in public scenes. Existing counting by regression methods either learn a single model for global counting, or train a large number of separate regressors for localised density estimation. In contrast, our single regression model based approach is able to estimate people count in spatially localised regions and is more scalable without the need for training a large number of regressors proportional to the number of local regions. In particular, the proposed model automatically learns the functional mapping between interdependent low-level features and multi-dimensional structured outputs. The model is able to discover the inherent importance of different features for people counting at different spatial locations. Extensive evaluations on an existing crowd analysis benchmark dataset and a new more challenging dataset demonstrate the effectiveness of our approach.
Contribution Highlights
- This is the first study that achieves robust crowd counting by mining local feature importance and sharing visual information among spatially localised regions in a scene.
- This is achieved by considering a single multi-output ridge regression model for localised crowd counting which has advantages over both existing global approaches in providing local estimates and existing local approaches being more scalable.
- We introduce a new public scene dataset of over 60,000 pedestrian instances for crowd analysis. To our best knowledge, it is the largest dataset to date with the most realistic and challenging setting of a crowded scene in a public space.
Citation
-
Feature Mining for Localised Crowd Counting
K. Chen, C. C. Loy, S. Gong, and T. Xiang
in Proceedings of British Machine Vision Conference, 2012 (BMVC)
PDF Extended Abstract Poster
Images

A flow chart illustrating the processing pipeline of global and local counting by regression methods, and our multi-output model. We consider that localised feature importance mining and information sharing among regions are two key factors for accurate and robust crowd counting, which are missing in all existing techniques.

A multi-output regression framework for localised crowd counting by feature mining. (Step-1) We first infer a perspective normalisation map. (Step-2) Given a set of training images, we extract low-level imagery features, including local foreground, edges and texture features, from each cell region. (Step-3) Local features from each cell are used to construct a local intermediate feature vector before all local intermediate feature vectors are concatenated into a single ordered (location-aware) feature vector. (Step-4) A multi-output regression model based on multivariant ridge regression is trained using the single concatenated feature vector and the vector, each element being actual count in each region, as a training pair. Given a new test frame, features are extracted and mapped to the learned regression model for generating a structured output that estimates the crowd count in each local region simultaneously.
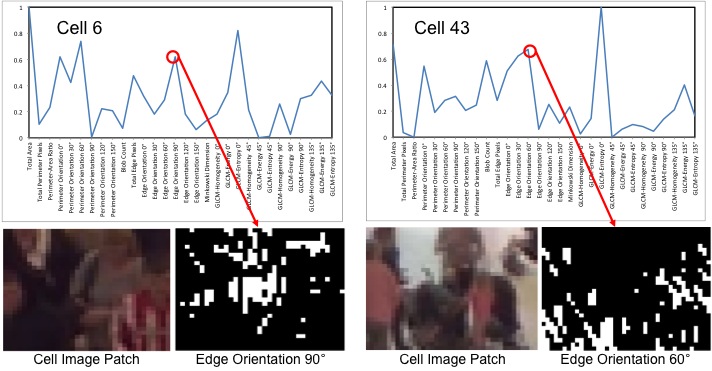
Local feature mining from one Close-to-Camera Cell 6 and one Away-from- Camera Cell 43 selected from the grid image in Figure 1. For each cell, we also show an example of image patch and together with the extracted edge at specific orientation. The horizontal axes of the two plots represent the features described in Section 2.1 of the paper.

The figures depict the weight contributions of neighbouring cells to cells 11, 51, and 55, which are highlighted using black boxes (refer Figure 1 for cell index). Red colour in the heat maps represents a higher weight contribution i.e. more information sharing.
Datasets and Codes

A dataset collected from a publicly accessible webcam for crowd counting and profiling research. Over 60,000 pedestrians were labelled in 2000 video frames.
Details ...