From Semi-Supervised to Transfer Counting of Crowds ICCV'13

Three-dimensional embedding of crowd patterns obtained using multi-dimensional scaling. Each point corresponds to a global feature vector of crowd pattern of a video frame. Every point is encoded by colour so that points with higher crowd density are red and points with fewer people are blue.
Introduction
Regression-based techniques have shown promising results for people counting in crowded scenes. However, most existing techniques require expensive and laborious data annotation for model training. In this study, we propose to address this problem from three perspectives: (1) Instead of exhaustively annotating every single frame, the most informative frames are selected for annotation automatically and actively. (2) Rather than learning from only labelled data, the abundant unlabelled data are exploited. (3) Labelled data from other scenes are employed to further alleviate the burden for data annotation. All three ideas are implemented in a unified active and semi-supervised regression framework with ability to perform transfer learning, by exploiting the underlying geometric structure of crowd patterns via manifold analysis. Extensive experiments validate the effectiveness of our approach.
Contribution Highlights
- We show that coherent and meaningful multi-source based video synopsis can be constructed in an unsupervised manner by learning collectively from heterogeneous visual and non-visual sources. This is made possible by formulating a novel Constrained-Clustering Forest (CC-Forest) with a reformulated information gain function that seamlessly handles multi-heterogeneous data sources dissimilar in representation, distribution, and dimension.
- The proposed approach is novel in its ability to accommodate partial or completely missing non-visual sources.
- We demonstrate the usefulness of our framework through generating video synopsis enriched by plausible semantic explanation, providing structured event-based summarisation beyond object detection counts or key-frame feature statistics.
Citation
Images
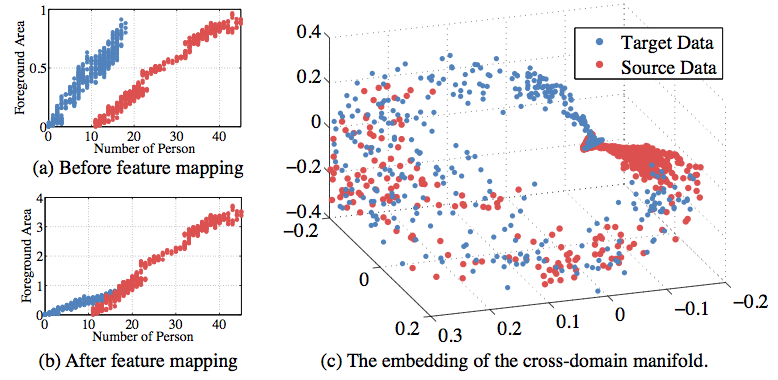
(a)-(b) Performing feature mapping using the corresponding points to align the feature range of ucsd and hallway datasets. (c) The embedding of the cross-domain manifold using the source data ucsd (red dots) and target data hallway (blue dots).
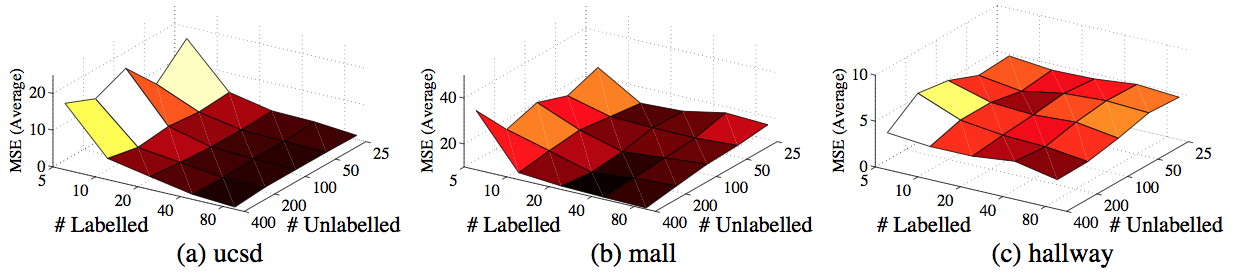
Adding more unlabelled data improved the counting performance in semi-supervised counting.

Count estimation performance using three different labelled data selection methods. The first row reports the average MSE whilst the second row shows the associated standard deviation plots. The 'm-landmark' is the proposed active selection method
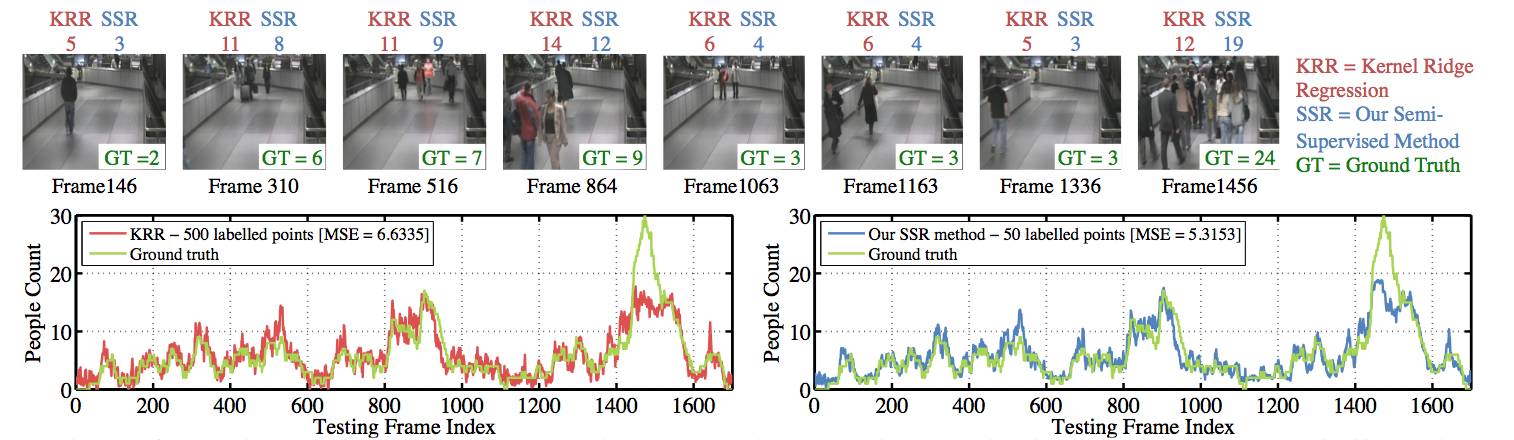
A comparison of the actual counting performance between KRR (kenel ridge regression method without semi-supervised learning) and our full active semi-supervised regression method on the hallway dataset. Note that our method achieved 20% reduction in mean squared error with just 10% of labelled samples as compared to the KRR.

Comparison against the state-of-the-art methods: GPR = Gaussian Processes Regression, CA-RR = Cumulative Attribute Ridge Regression, SSR = the proposed Semi-Supervised Regres- sion method. The performance is measured in mean squared error.
Datasets and Codes

A dataset collected from a publicly accessible webcam for crowd counting and profiling research. Over 60,000 pedestrians were labelled in 2000 video frames.
Details ...