Stream-based Joint Exploration-Exploitation Active Learning CVPR'12
Introduction
Learning from streams of evolving and unbounded data is an important problem, for example in visual surveillance or internet scale data. For such large and evolving real-world data, exhaustive supervision is impractical, particularly so when the full space of classes is not known in advance therefore joint class discovery (exploration) and boundary learning (exploitation) becomes critical. Active learning has shown promise in jointly optimising exploration-exploitation with minimal human supervision. However, existing active learning methods either rely on heuristic multi-criteria weighting or are limited to batch processing. In this paper, we present a new unified framework for joint exploration-exploitation active learning in streams without any heuristic weighting. Extensive evaluation on classification of various image and surveillance video datasets demonstrates the superiority of our framework over existing methods.
Contribution Highlights
- We show how stream-based joint exploration-exploitation can be achieved using a unified active learning criterion. The proposed method makes immediate query decisions at each instance, and is thus computationally suitable for streaming data and large-scale learning tasks that demand on-the-fly interactive labelling.
- Our method is formulated as a nonparametric Bayesian model that adapts its complexity and exploration-exploitation balance to the data, without any heuristics or manual tuning of parameters. Its performance is thus reliable and stable across many datasets.
- We leverage the Pitman-Yor Processes (PYP) as a class prior in active learning, which gives improved performance on real-world long-tailed problems for which existing methods are weak.
Citation
-
Stream-based Joint Exploration-Exploitation Active Learning
C. C. Loy, T. M. Hospedales, T. Xiang, and S. Gong
in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 1560-1567, 2012 (CVPR, Oral)
PDF
Images

In many vision problems (e.g. classification of face images on the internet), the class frequency is distributed in a heavy-tailed power-law fashion.
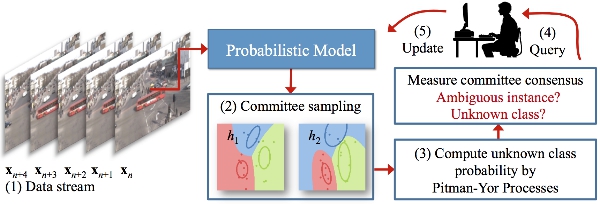
For stream-based active learning we iteratively: (1) receive an instance from the data stream; (2) draw two random hypotheses from the model posterior to form a committee. The hypotheses are model variants sampled from the posterior distribution over the parameters of the model. (3) for each hypothesis, compute the posterior under the PYP assumption; (4) query the instance if the two hypotheses disagree on its classification, or they both assign the instance to an unknown class; (5) include the labelled instance in the training set to refine the classifier; The iteration stops when a criterion is met, e.g. the query budget is exhausted.
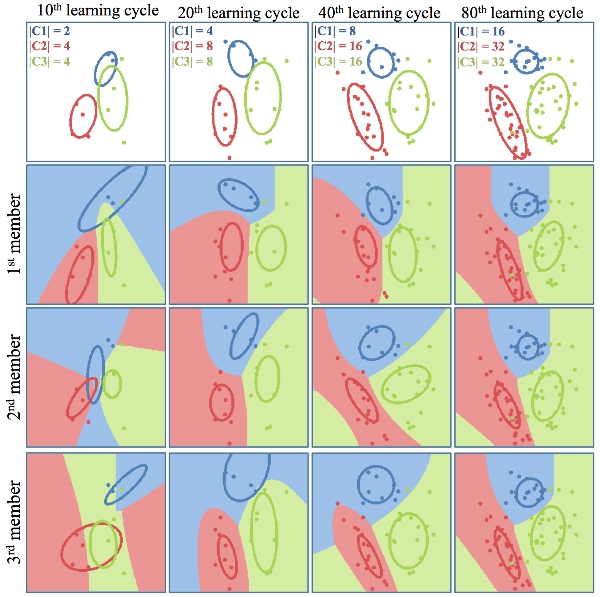
Committee members with different decision boundaries can be formed by sampling different mean and covariance estimates from the posterior probability distribution over the model parameters. Sampling the posterior produces members whose parameters estimate differ most when the number of data n is low and tend to agree when n is high.
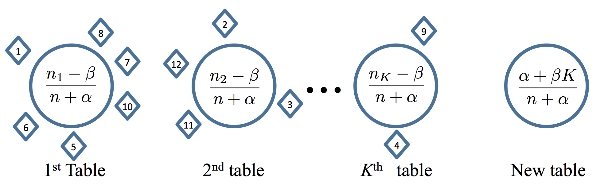
Pitman-Yor Processes with \((\alpha, \beta)\) seating plan, where numbered diamonds represent customers, and the large circles represent tables.

Qualitative comparison of uncertainty regions addressed by both the QBC and the proposed approach. Red colour suggests high query preference, whilst blue colour suggests low query preference.

Using the Labeled Yahoo! News face database, we plot the empirical class density (number of instances in each class) vs. density rank across all classes in a log-log scale. We also plot the number of unique classes drawn from a Pitman-Yor processes (PYP) and Dirichlet processes (DP). A pure power law relationship would be a perfect straight line on a log-log scale.
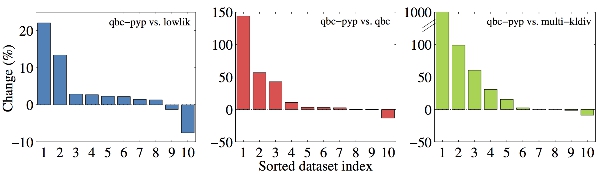
Percentage improvement of average classification accuracy for qbc-pyp over prior models for all datasets.
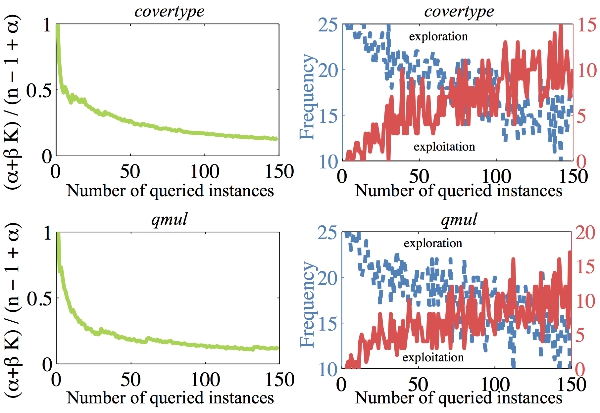
(Left figures): Pitman-Yor prior on unknown class reflects the weight assigned to finding new classes. (Right figures): Automatic switching between exploration and exploitation.
Datasets and Codes
MATLAB code for performing stream-based joint exploration-exploitation active learning.