POP: Person Re-Identification Post-Rank Optimisation ICCV'13
Introduction
Owing to visual ambiguities and disparities, person re-identification methods inevitably produce suboptimal rank list, which still requires exhaustive human eyeballing to identify the correct target from hundreds of different likely candidates. Existing re-identification studies focus on improving the ranking performance, but rarely look into the critical problem of optimising the time-consuming and error-prone post-rank visual search at the user end. In this study, we present a novel one-shot Post-rank OPtimisation (POP) method, which allows a user to quickly refine their search by either “one-shot” or a couple of sparse negative selections during a re-identification process. We conduct systematic behavioural studies to understand user’s searching behaviour and show that the proposed method allows correct re-identification to converge 2.6 times faster than the conventional exhaustive search. Importantly, through extensive evaluations we demonstrate that the method is capable of achieving significant improvement over the state- of-the-art distance metric learning based ranking models, even with just “one shot” feedback optimisation, by as much as over 30% performance improvement for rank 1 re-identification on the VIPeR and i-LIDS datasets.
Contribution Highlights
- We formulate a systematic framework for re-id post-rank optimisation, largely unaddressed by the existing person re-identification literature.
- We introduce a new one-shot Post-rank OPtimisation (POP) model for very fast post-rank re-identification convergence with significant increase in re-id accuracy.
- Our model not only improves 2.6 times of search efficiency compared to the typical exhaustive search strategy, but also brings about as much as over 30% performance improvement for rank 1 re-identification over current distance metric learning and ranking models. This is based on “one shot” user negative selection only.
Citation
Images

Human-in-the-loop re-identification is needed to resolve the inherent visual ambiguities and disparities caused by different camera view orientations, occlusion, and lighting variations.

A strong negative is a highly ranked, but confusing match in a machine generated suboptimal rank list with clear visual dissimilarity to the probe image, whilst a weak negative is a visually similar but wrong match in the same rank list.
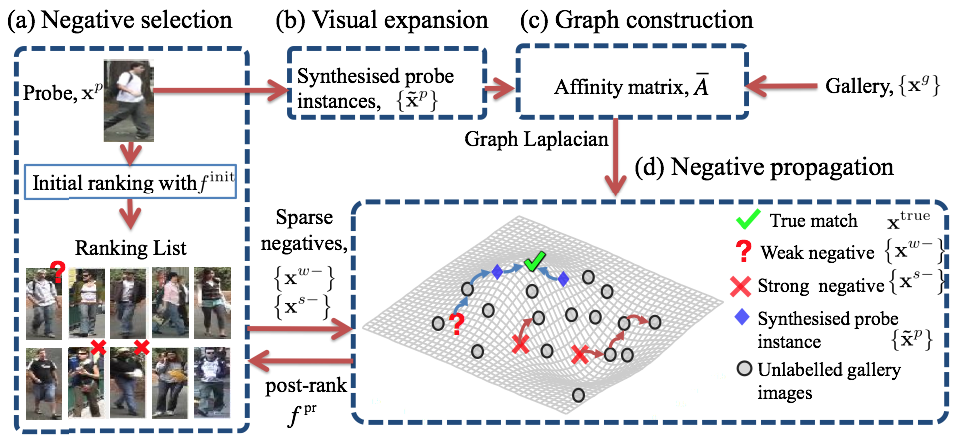
An overview of the proposed one-shot Post-rank OPtimisation (POP) model for person re-identification. A user only needs to select a single strong negative feedback, and optionally a few weak negatives, to trigger an automated refinement of the suboptimal rank list.

After each round of negative mining, we add new negative selections to a cumulated strong negative sets collected from previous rounds (or also weak negative sets if weak negatives were selected). As more negatives are accumulated, the classification boundary is refined, increasing the separation between the true match and other strong negatives. The figure shows (a) three-dimensional embedding of gallery images obtained using multi-dimensional scaling after the first round of negative selection, (b) the embedding after the second round. The gallery images are colour coded according to their new ranking score. The shrinking region of bright yellow colour indicates the effectiveness of negative mining in demoting initial false matches.

The probe and the true match are highlighted respectively with red and green bounding boxes. In the middle we show the returned top 15 ranked results. The selected strong negative is denoted by a red cross. One can observe that the POP is effective in demoting candidates who have similar appearances to the selected strong positives. For instance, as shown in (b), when a user selected the first candidate as strong negative, both the first and second candidates who were wearing brown jackets were removed from the top ranks.
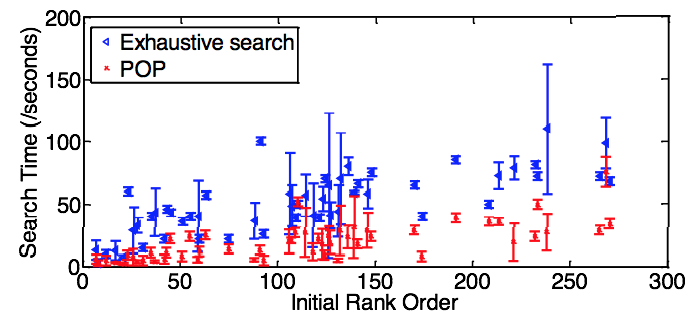
Search time (in second) comparison, between exhaustive search and POP search, both of which are initialised by l1-norm matching.
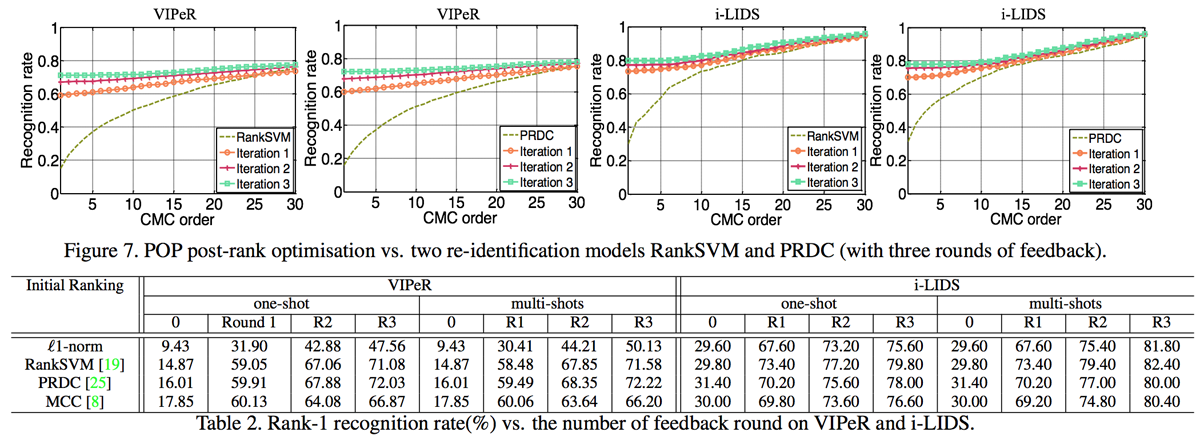
Figure: POP post-rank optimisation vs. two re-identification models RankSVM and PRDC (with three rounds of feedback).
Table: Rank-1 recognition rate(%) vs. the number of feedback round on VIPeR and i-LIDS.
Supplementary Materials
- Data partition, CMC curves, and weak+strong negatives annotations.Download